



当連載の初回では、世の中の変化、来るだろう未来を大きく捉え、ITとの関連性・可能性について導入部分をお話ししました。前号では、その具体例の1つとしてデータの活用によって、デジタルの量と質がアナログな人間の行動を予想しえることについて書きました。その背景には、情報格納やアクセスの格段なテクノロジーの進化がある話をしました。
さて今号では、そのデータ分析・活用として注目を浴びているビッグデータの利用用途について、もう少し掘り下げて考え、ヒントを見つけていきたいと思います。
「ビッグデータ」という言葉は5年くらい前に流行り始め、瞬く間に書籍や雑誌でも取り上げられるようになりました。「いまお持ちのデータが宝の持ち腐れになってないか」「データを活用すると情報に変わり、今まで見えていなかったものが見えて来る」こんな論調が多いかと思います。
そういった側面ももちろんあり、今回もそういった用途について取り上げたいと思っていますが、意外と語られていないのは「使い勝手を良くする」側面でのビッグデータの利用です。
身近な例で考えてみましょう。
皆さんが普段から無意識に使っているGoogleの検索は、言う間でもなくビッグデータの宝庫です。
今では、英語でもGoogleが動詞化して辞書に載るほどですし、日本でも「ググる」と普通に使われるようになりました。Google検索で便利だなと思う機能の1つに、検索ワードが正確でなくても「もしかして、このワードではないですか?」とGoogleが検索ワードの候補を示してくれる機能があります。
図1 Googleの「もしかして」検索(c)Dolphere Ltd.
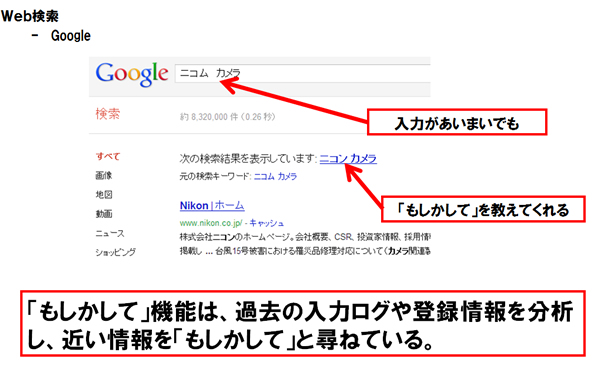
人間の曖昧なところを、人間が大量に入力した検索ワードの統計を基に推測して正しい検索ワードを導き出してくれているわけです。まさしく、量で質を創り出している例となります。
検索していると、検索ワードを入力しているそばから、プルダウンして候補を表示してくれる機能も便利ですね。Google Sugestと言われる機能で、これもこれまでの大量の人間の検索したワードを統計的に把握していて、瞬時に確率の高いものから順に表示してくれるわけです。入力の手間が省けるだけでなく、曖昧な記憶をこの候補で助けてくれる大変便利な機能です。
図2は、ある製品のエラーコードを調べようと入力していたら、候補が出て来た例です。
図2 Google Sugest機能(c)Dolphere Ltd.
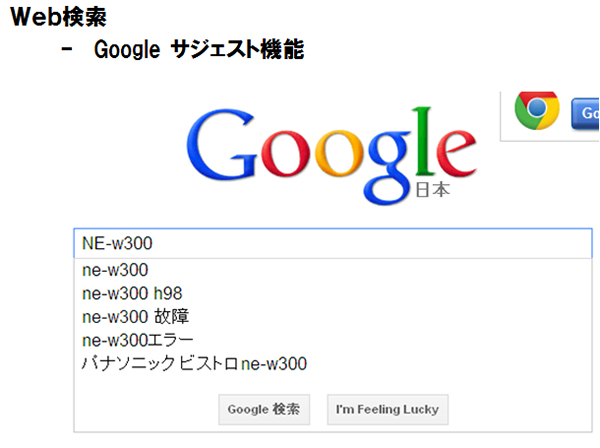
これにより、自分だけが引き起こした故障ではなく、頻繁に起きていて他の人も検索していることがわかります。もしかしたらリコールがかかっているかも知れないというヒントにもなったりします。このような他の人間の過去の入力から推測して、「あなたもそうなのでは?」と便利に示唆してくれる機能が「リコメンデーション」と呼ばれる機能です。
図3 Amazonの「リコメンデーション」機能(c)Dolphere Ltd.
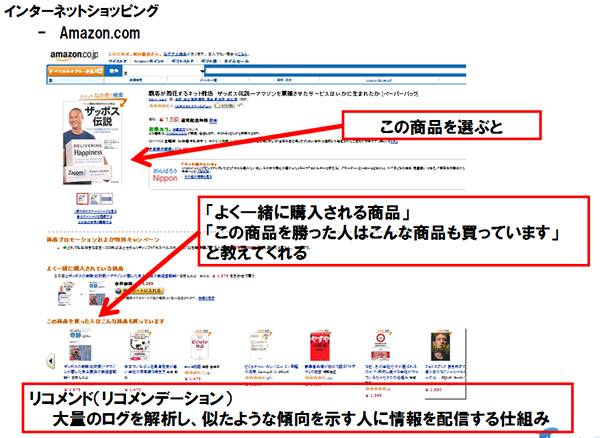
AmazonなどのECサイトで、本を買おうとすると、この本もいかがですか?とお勧めしてくれるあの機能がこのリコメンデーションです。ユーザーにとってはわざわざ検索して探すまでもなく欲しい品が表示されて便利ですし、売る側から見ても営業効率よく品をお勧め出来るわけです。
ただしここで、この便利さがなせる危険性についても示唆しておきたいと思います。
「フィルターバブル」と呼ばれている現象をご存じでしょうか。
検索アルゴリズムがどんどん賢くなり、ユーザーの過去の行動履歴を基にユーザーの嗜好を理解し示唆してくれるものですから、自分の嗜好や意図とは無関係に情報を得たい時でも、客観的に情報を得ることが難しくなってしまっている現象が近年起きています。
図4 フィルターバブルの脅威(c)Dolphere Ltd.

検索している人は、公平にネットで調べているつもりでも、自分の嗜好を理解している検索アルゴリズムは、自分に都合のいい情報ばかりを提示してくれてしまうわけです。昨年のアメリカの大統領選も、イギリスのEU離脱の時も、こういった情報の偏りが引き起こされて結果に影響したと言われています。
今や3分の2がソーシャルメディアから情報を収集していると言われている時代です。
判断を誤る危険性に大きくさらされていると心得ておくべきなのでしょう。
話をビッグデータの話に戻したいと思います。
このあと、ビッグデータの用途について書いていきますが、前述した「使い勝手向上」にビッグデータを活用する企業はまだごく限られています。当記事を読まれている読者には、ぜひこの戦略的な使い方も片隅に覚えておいてもらえればと思います。
さて、当連載の初号でも話しましたように、ITの使われ方が合理化の手段から、満足の手段へと変わりつつあります。ITが各企業に一通り行き渡ったという側面もありますが、大量データを格納でき、瞬時に分析出来る処理能力が付いて来たテクノロジー的背景も大きく寄与しています。そうなった時に、ではどういうデータ分析をするのが最も「満足」への提案となるのでしょうか。
図5の右側と図6に、大まかに用途を分類したものを載せました。
図5 合理化提案の時代から、満足提案の時代へ(c)Dolphere Ltd.
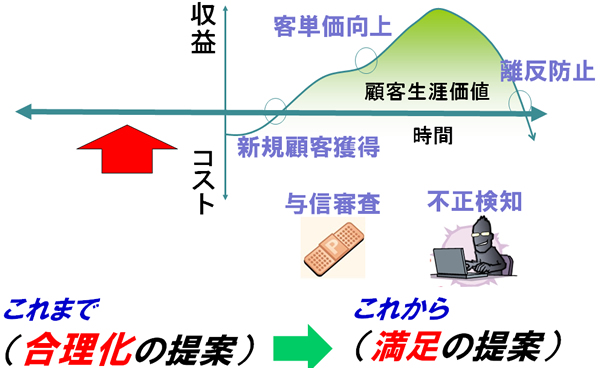
図6 データ分析の主な用途(c)Dolphere Ltd.

データ分析で何を予測するのかといった時に、人の行動の予測と、機械の予測とまず大きく2つに分けることが出来ます。ビッグデータというと、人の行動予測に使われていると思っている人が多いのですが、やはり機械の方が予測しやすく精度も高くなり、投資効果が期待しやすいのです。
図7はビッグデータの事例としては有名な事例となっていますが、機械の保守という作業を逆転の発想で、壊れてから保守するのではなく、壊れる前に保守をして業務継続を実現させようという解決策です。プロアクティブな保守です。
図7 プロアクティブな保守(c)Dolphere Ltd.

ユーザーにとっては、機械のコストも重要ですが、それよりも機械の故障によって業務が止まることの方が痛手であることが多いわけです。たとえ機械が多少高くなっても、壊れないのであればトータル運用コストは下がるので高い機械を購入したいと思うわけです。機械にセンサーを取り付けて、機械の稼働状況をいろいろな角度からセンサーで読み取り、故障に至るまでの動きを分析して傾向から予知することが出来れば、「壊れそう」な時に事前に保守をすることが出来るようになります。
ビッグデータを活用しこういう使い方をすることで、「日本の機械は多少高いが、他国の安価なものよりも安くつく」と評価をいただくことが出来るようになるわけです。このセンサーとの連動に関しては、次号で深く取り上げたいと思います。
さて、もう一方のビッグデータの用途は、やはり人間の行動の予測になります。
図5、図6に戻りますが、大きく5つに分類することが出来ます。
このうち「与信審査」と「不正検知」は即効性もあり、効果の高い用途になります。
ソリューションとしては「満足」というよりはネガティブな事象の予防になりますが、人間はポジティブなものよりはネガティブな方にパターンが出やすいと言われています。
少子高齢化の背景の中、「作れば作るほど売れた時代」ではなくなった今、期待度の高い用途は残りの3つかと思います。「新規顧客獲得」「客単価の向上」「離反防止」です。
受注データを貯めている企業は多いと思います。このデータを分析することによって、顧客の行動パターンを見つけ、そのパターンを辿る顧客にアプローチする戦略です。前述のリコメンデーションの機能は、この中の「客単価の向上」に当てはまりますね。
多分、多くの企業はこの中でも「新規顧客獲得」に一番期待を置くかも知れませんが、もし効果の高い順に着手されたいのでしたら、「離反防止」がおススメです。人間はモノを買う時は衝動的なことがありますが、辞める時は比較的理由があって、パターンとして浮き彫りになりやすいからです。
学校を退学しそうな生徒を事前に見つけたり、会員が退会しそうな直前に見つけ引き留めることに使われたり出来ます。
さて、用途の分類はわかりましたが、実際にはどんなデータ分析をするのでしょうか。
データ分析手法の王道を理解しておくと、今後ビッグデータを活用する際に、より用途を思いつきやすくなると思いますので、最後に紹介しておきます。
大きく3つの手法が現在主流となっていて使われています。
一番わかりやすいのが「アソシエーション」と呼ばれる分析です。
いわゆる要素間の関連付けを関連の強さで示した分析です。どの商品とどの商品が併売傾向が強いかとか、どの原因とどの結果が関連性が強いかといったものを見つける時に使います。一昔前に「ビールの隣におむつを置くとビールの売り上げが上がる」という都市伝説みたいな話が出たことがありましたが、これなどはまさしくこのアソシエーションの分析結果になります。
図8 データ分析手法 「アソシエーション」(c)Dolphere Ltd.

「決定木分析」は、データ分析の手法の中では最も利用頻度の高いと言われている手法です。
前号でも言いましたが、「2割の優良顧客が8割の売り上げに貢献する」といったような「ニッパチの法則があります。
図9 「ニッパチの法則」 効率よく営業活動を(c)Dolphere Ltd.
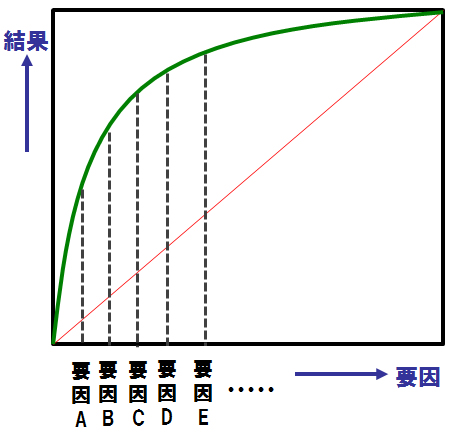
このような傾向がある時に、その2割をどうやって見つけるか、それを援助するのがこの「決定木分析」です。まず図10を見ていただいた方がわかりやすいかと思います。
図10 データ分析手法 「決定木分析」(c)Dolphere Ltd.
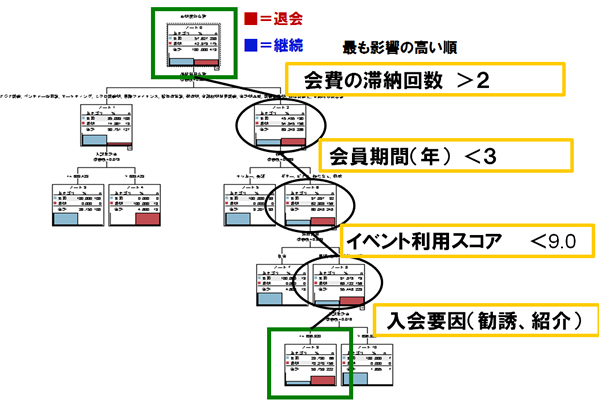
何かの結果(図10では退会という結果)に対して、様々な要因が考えられますが、どの要因が結果に対して影響しているかをこのようにツリー構造で表記する手法のことです。ツールを使うと、自動的にこの図を導き出してくれます。この分析を行うことで、その結果に至りやすい要因が見えて来ますので、その要因を辿っている顧客に事前の策が打てるようになります。
前号でお話しした「ターゲット」というスーパーの事例も、妊娠した女性の妊娠する前の購買パターンを見つけ出して、事前にピッタリのグッズ(おむつや揺りかごなど)のDMを出していました。まさしく決定木分析をした結果わかったことです。
さて3番目の手法は「セグメンテーション」と呼ばれる手法です。
図11 データ分析手法 「セグメンテーション」(c)Dolphere Ltd.
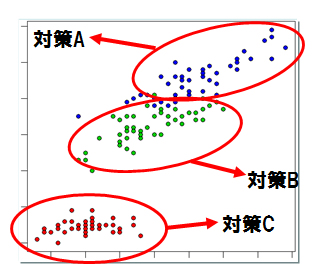
流行的な観点で言いますと、今後この手法で分析することが増えるだろうと言われている手法です。
これは、数ある顧客なり商品なりを分類分けする統計手法です。人間も勘で結構グループ分けして考える癖を持っているものですが、それは要素(要因)が2つや3つの時までです。
受注データのような実際の業務データを分析しようとすると、時期や性別、年代層、地域、購買商品、家族構成、…等々、膨大な数の要因があって、これらを特徴ある毎のグループに分けるのは至難の業です。
その作業を統計分析ツールに任せてしまおうというやり方です。
例えば、こんなやり方で営業効率を上げることが出来ます。
この「セグメンテーション」の手法を使って顧客購買情報から4~5つ程度の特性あるグループを作り、顧客をそれぞれに分類します。そしてその各グループ毎の商品売り上げトップ10をリストアップします。
そのグループに所属しているお客様に、その商品売り上げトップ10のうち、まだそのお客様が買っていない残りの9つの商品を紹介すれば購買確率は大きく上がるわけです。
無暗に全員に全体のトップ10を勧めるよりは、特性毎にそのグループの嗜好を理解した上でのトップ10を勧めた方が、顧客も満足度が高くなるのです。まさしくニッパチの法則ですよね。
最近電車を乗っているとJRの構内に大きなジュースの自販機を見かけます。
図12 自販機がセンサーを駆使して嗜好を読み取る(c)Dolphere Ltd.

この自販機は、中央の上の方にカメラが搭載されていて、ジュースを買いに来た人の年齢と性別を推定しているのをご存じですか?まさしくこのセグメンテーションの手法を利用して、性別や年齢を判定した上で、その層に好まれているジュースを「オススメ」として自販機に表示しているのです。
聞くところによると売り上げ1.5倍の効果があったとか。
こういった購入者の属性(要因)を取得するのに、近年センサー技術が見直されて来ました。
これがいま流行り言葉となっています「IoT」です。
このテーマについて、次回掘り下げて紹介してみたいと思います。
乞うご期待ください。

井下田久幸いげたひさゆき
ドルフィア株式会社代表取締役
1961年生まれ。青山学院大学理工学部卒業後、日本IBMに入社。出世コースをばく進するが、38歳のとき社員数16人のITベンチャーに志願し転職。程なく倒産の危機に遭遇し、マーケティング職務を担う傍ら、…
ビジネス|人気記事 TOP5
AIも人間も「勉強が大事」というお話
大越章司のコラム 「デジタル変革(DX)への対応とは」
初めてのニューヨーク講演
大谷由里子のコラム 「大谷由里子の人づくり日記」
お金持ちになったら何したい?
大谷由里子のコラム 「大谷由里子の人づくり日記」
創業守成
宗次徳二のコラム 「宗次流 独断と偏見の経営哲学」
高い専門性を持つ人のパーソナリティー
青柳教恵のコラム 「ヒューマンコミュニケーション術・・・会話の力」
講演・セミナーの
ご相談は無料です。
業界25年、実績3万6700件の中で蓄積してきた
講演会のノウハウを丁寧にご案内いたします。
趣旨・目的、聴講対象者、希望講師や
講師のイメージなど、
お決まりの範囲で構いませんので、
お気軽にご連絡ください。